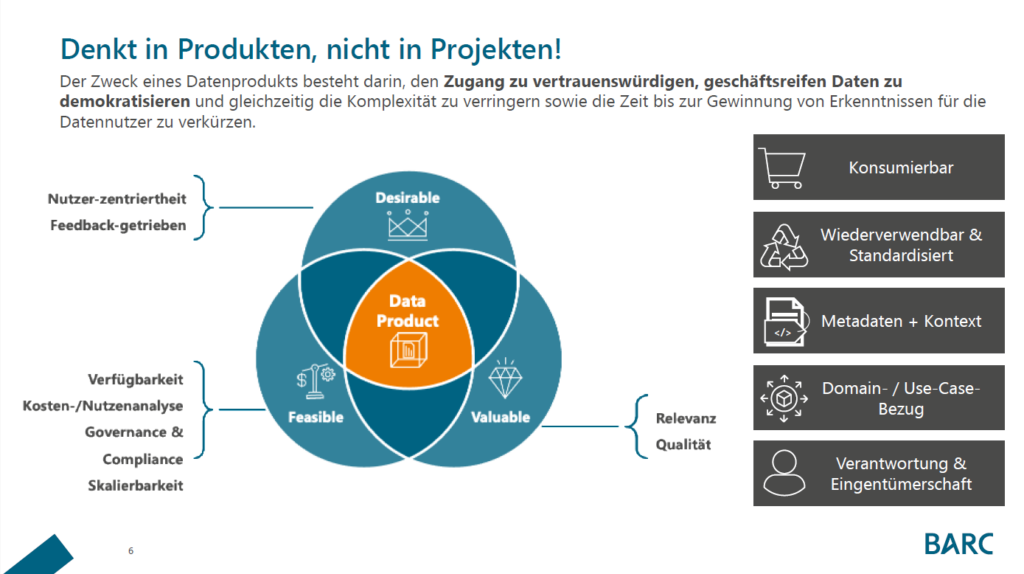




Einleitung
Wer schon einmal ein SAP BW-Migrationsprojekt begleitet hat, weiß: Je größer und komplexer das System, desto wichtiger ist es, effizient und möglichst standardisiert vorzugehen. Die Migration von SAP BW nach SAP Datasphere stellt Unternehmen außerdem noch vor die Herausforderung, von Ihrer gewohnten On-Premise-Lösung in eine Public-Cloud-Umgebung zu wechseln. Dieser Transformationsprozess erfordert nicht nur eine sorgfältige Planung, sondern auch ein klares Zielbild, wie man die Vorteile der neuen Cloud-Technologie optimal nutzen und gleichzeitig bewährte Geschäftslogiken bewahren kann.
Für letzteren Aspekt bietet sich die SAP BW Bridge an – sie fungiert als Bindeglied zwischen den Systemen und ermöglicht die Migration bestehender Modelle und Geschäftslogiken. In diesem gemeinsamen Blogbeitrag vom Beratungsunternehmen NextLytics und Softwareanbieter bluetelligence soll es anhand eines Praxisbeispiels aus einem Projekt darum gehen, wie dieser Ansatz erfolgsversprechend durchgeführt werden kann. Denn: Die Bridge zu nutzen bedeutet natürlich, teilweise auf Vorteile zu verzichten, die ein Greenfieldansatz in Datasphere verspricht. Dem gegenüber bietet sie als „schnellere“ Migrationsoption“ jedoch viele Vorteile, die es abzuwägen lohnt. Für den Einsatz der BW Bridge sprechen insbesondere folgende Gründe:
- Investition in BW-Modelle: Oft wurde viel Aufwand in die Entwicklung spezifischer BW-Modelle gesteckt, die komplexe Business-Logiken und individuelle Datenflüsse – teilweise mit umfangreicher ABAP-Logik – enthalten.
- Eingeschränkte Verfügbarkeit von CDS-basierten Extraktoren: In Fällen, in denen SAP-basierte Quellsysteme noch nicht die erforderlichen CDS-Extraktoren bereitstellen (z.B. bei SAP ECC-Systemen), müssen klassische S-API-Extraktoren genutzt werden. Es wird jedoch davon abgeraten, diese direkt an SAP Datasphere anzubinden, da Einschränkungen bestehen, beispielsweise wenn DataSources zwingend Selektionsfelder benötigen oder bestimmte Delta-Verfahren nicht unterstützt werden.
- Mangel an spezifischen Kompetenzen: Häufig verfügen Teams über umfangreiche BW- und ABAP-Expertise, während Know-how zu SQL oder Python, die in SAP Datasphere genutzt werden – nicht ausreichend vorhanden ist, um die Modelle nativ neu zu erstellen.
In unserem folgenden realen Projektbeispiel trafen all diese Faktoren zu. Es handelte sich um ein umfangreiches, historisch gewachsenes BW-System eines Energieversorgers mit hochspezialisierten Modellen, die den Besonderheiten des komplexen und stark regulierten Energiemarktes Rechnung tragen. Das Projektziel bestand darin, die bestehenden Modelle, Business-Logiken und Datenflüsse zu erhalten und lediglich den Reporting-Layer in SAP Datasphere neu abzubilden. In diesem Kontext erwies sich auch der Einsatz der Performer Suite von bluetelligence als entscheidender Erfolgsfaktor für eine effiziente und zielgerichtete Migration.
Zielbild und Vorgehensweise
Bevor wir das detaillierte Zielbild des Projektes vorstellen, ist es wichtig, eine Besonderheit der BW Bridge in Verbindung mit SAP Datasphere zu erläutern. Obwohl Queries bei der Migration in die BW Bridge übertragen werden können, können sie nicht wie im klassischen BW-System ausgeführt oder als Quelle für andere Datenziele verwendet werden. Stattdessen werden Queries in der BW Bridge als Metadaten bereitgestellt. Das bedeutet, sie können importiert und als Grundlage für den Entity-Import in SAP Datasphere genutzt werden. Diese Eigenschaft spielt eine zentrale Rolle in unserer Vorgehensweise.
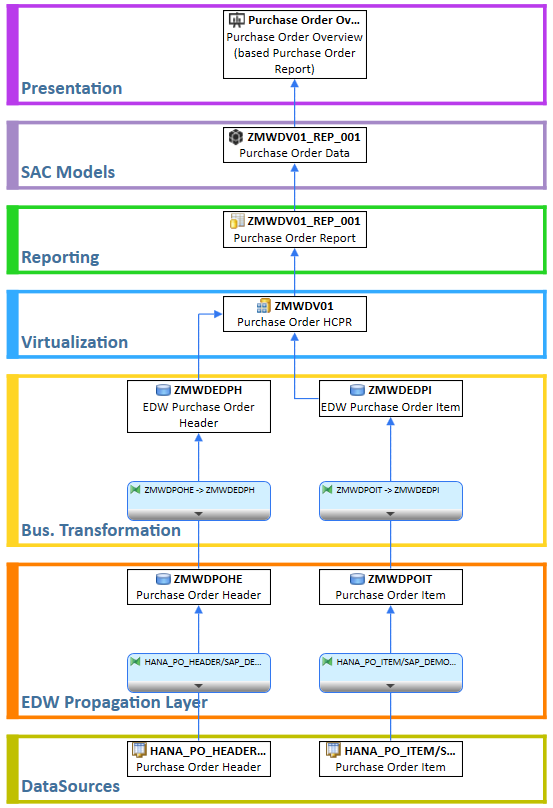
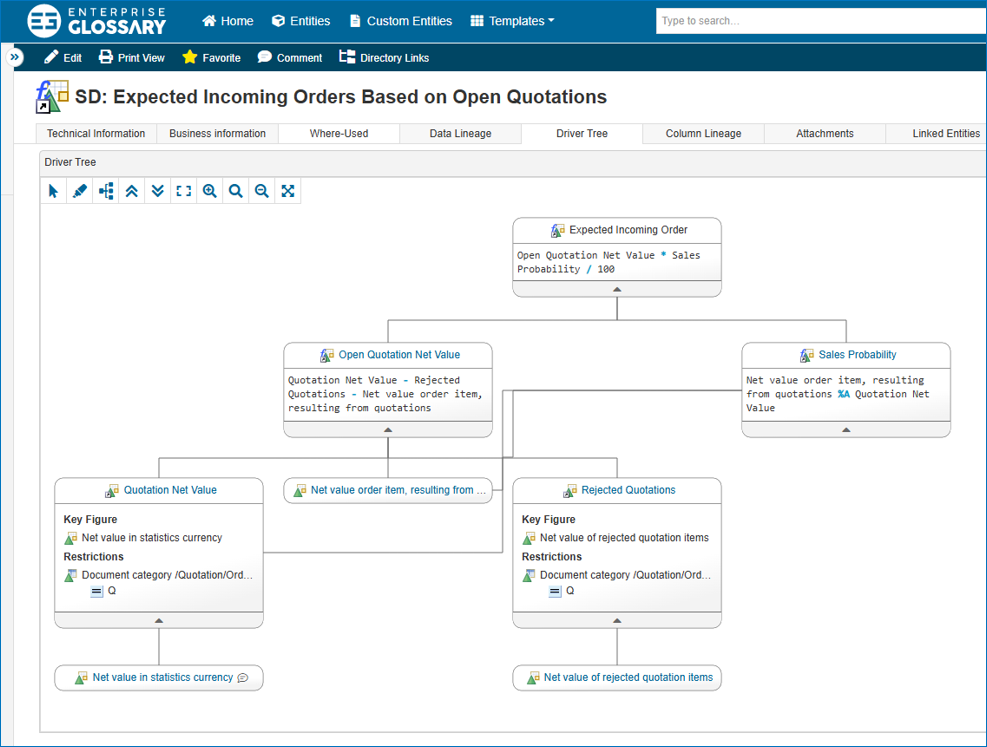
Das folgende Schaubild veranschaulicht das Zielbild des Projekts:
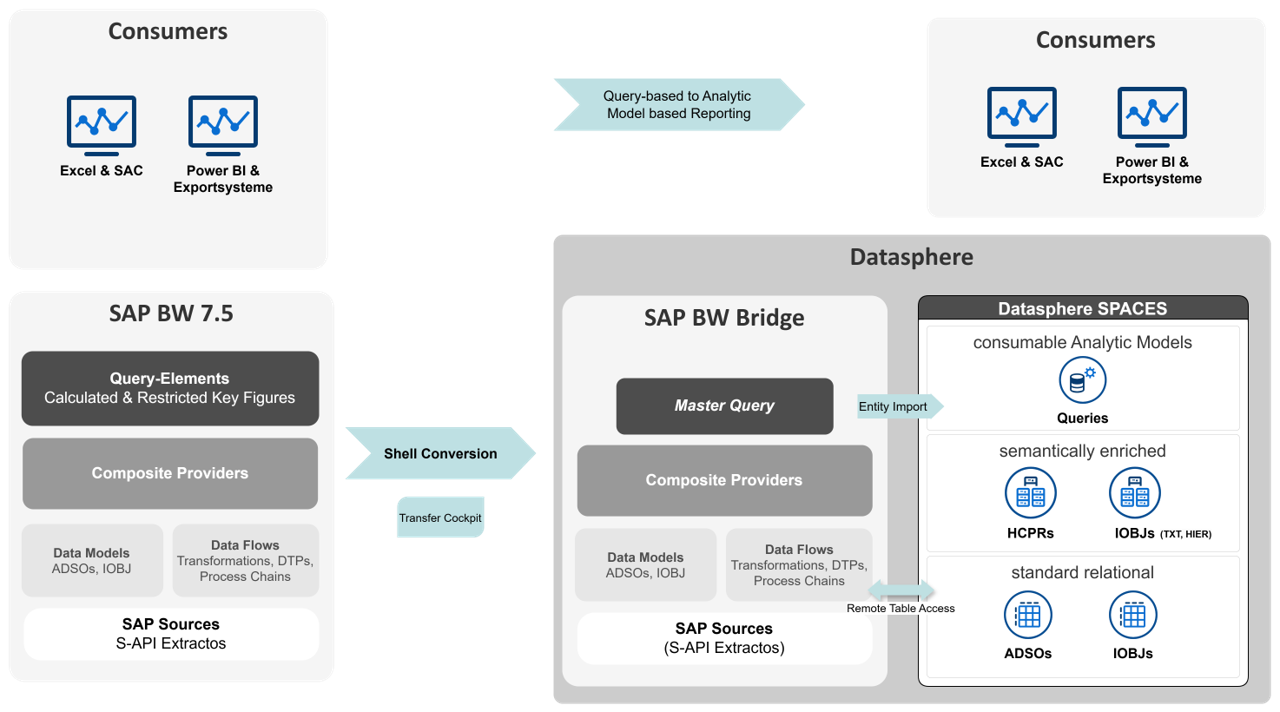
Im Rahmen des Projektes wurden mehrere zentrale Schritte definiert, die für die Migration von SAP BW nach SAP Datasphere entscheidend waren:
1.Toolgestützte Übertragung via Shell Conversion:
- Migration der Modelle und Datenflüsse bis zum Composite Provider
2. Entwicklung und Übertragung von Master-Queries:
- Abbildung aller globalen und lokalen berechneten und eingeschränkten Kennzahlen sowie aller für das Reporting relevanten Merkmale
- Erstellung pro Composite-Provider
- Übertragung mittels Shell Conversion
3. Generierung der Analytics Models:
- Entity-Import der Master-Queries
- Automatische Erstellung der Analytics Models basierend auf importierten Queries
4. Umstellung des Reportings:
- Umstellung des query-basierten Reportings auf Analytics Models in den verschiedenen Frontend-Tools
Durch den gezielten Einsatz des Entity-Imports konnten wir einen Großteil der erforderlichen Objekte automatisch generieren lassen und damit den Zeitaufwand für die Modellierung in Datasphere erheblich reduzieren.
Die Darstellung in dem Schaubild ist bewusst vereinfacht und fokussiert sich auf die Kernaspekte der Migration. Das vollständige Konzept umfasst zusätzliche wichtige Komponenten:
- Weitere Non-SAP Quellsysteme
- Detailliertes Layer-Konzept
- SPACE-Konzept für die Zusammenarbeit von Central IT und Fachbereichen
- Implementierung von Berechtigungen über Data Access Controls
- Berücksichtigung spezifischer Anforderungen je nach Datenabnehmer (z.B. via ODBC oder OData)
Für detaillierte Informationen können Sie sich gerne den NextLytics-Blogbeitrag zur Referenzarchitektur SAP Datasphere ansehen: Blog Nextlytics: Datasphere Referenzarchitektur – Überblick & Ausblick
Praktischer Einsatz der Performer Suite im Projekt
Master-Query-Analyse
Eine der zentralen Herausforderungen des Projekts bestand also darin, die Kennzahl-Definitionen als Vorlage für die Master-Queries zu erstellen – dafür mussten wir die Strukturen einer Vielzahl an Queries aus dem BW-System des Kunden analysieren. Schon in der Planungsphase war uns klar, dass wir dafür eine leistungsstarke, toolgestützte Lösung benötigen würden. Als Partner von bluetelligence kannten wir die Stärken der Performer Suite und entschieden uns daher für den Einsatz einer zeitlich begrenzten Lizenz im Projekt.
Ziel war es, pro Composite Provider eine Master Query zu erstellen, die alle globalen und lokalen berechneten und eingeschränkten Kennzahlen sowie alle für das Reporting relevanten Merkmale enthält. Um nur die für das Reporting relevanten Kennzahlen zu übernehmen, analysierten wir zunächst mit der System Scout Analyse Data Loads and Usages alle in den letzten 18 Monaten ausgeführten Queries:
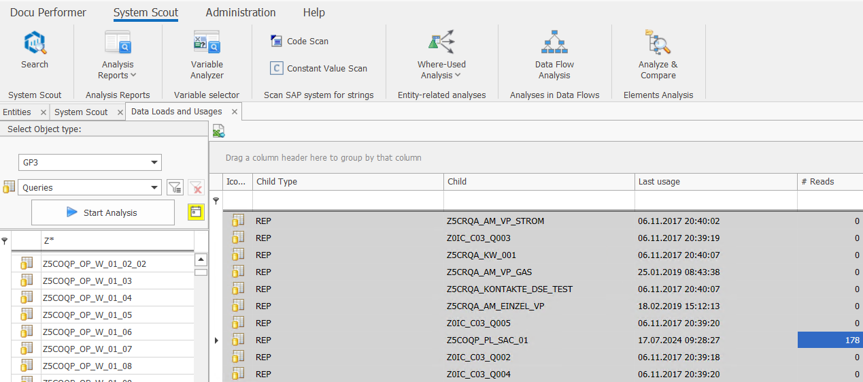
Diese Analyse lieferte uns pro Composite Provider eine Liste aller relevanten Queries. Für eine zentrale Auflistung der Definitionen aller globalen und lokalen berechneten und eingeschränkten Kennzahlen griffen wir auf den Query SetCard Designer zurück. Wir erstellten eine SetCard, in der wir alle erforderlichen Informationen der in den Queries verwendeten Kennzahlen erfassten:
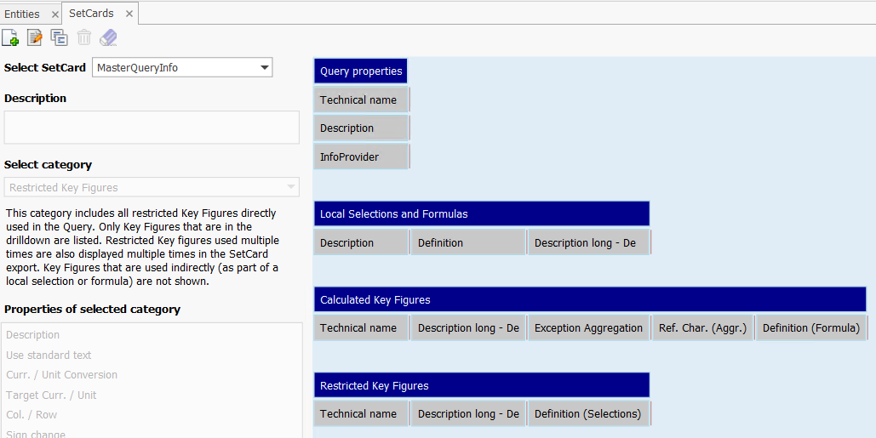
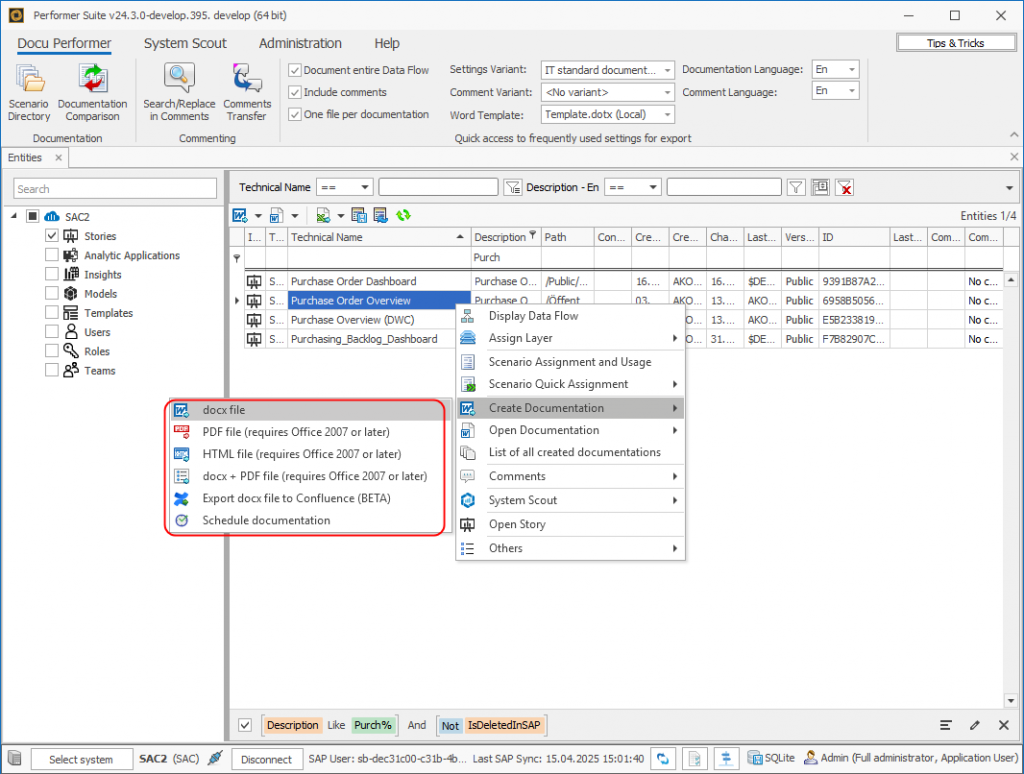
Mit Hilfe des Docu Performers (ein Tool der Suite) konnten wir anschließend die Queries gemäß unserer SetCard-Vorlage nach Excel exportieren. Dabei war es wichtig, die Einstellung One file per documentation zu deaktivieren, um nicht für jede Query eine separate Excel-Datei zu erzeugen. Das Resultat war eine konsolidierte Übersicht der Kennzahl-Informationen pro Composite Provider. Diese Übersicht nutzten wir als Vorlage für die Erstellung der Master-Queries.
Planung der Migration und Datenfluss-Analyse
Zu Beginn der Migration entwickelten wir einen strukturierten Wellenplan, der auf eine schrittweise Umstellung während der Projektlaufzeit setzte, anstatt eines einzigen großen Big Bang am Ende. Dieser Ansatz ermöglichte es uns, Reporting-Szenarien iterativ von SAP BW nach SAP Datasphere zu migrieren, zu testen und User Acceptance Tests (UAT) mit den Fachbereichen durchzuführen.


Diese Strategie bot mehrere Vorteile:
- Risikominimierung durch schrittweise Umstellung
- Frühzeitige Stabilisierung der neuen Umgebung
- Kontinuierliches Lernen und Optimieren der Vorgehensweise
- Flexibilität, um auf Herausforderungen zu reagieren, ohne das Gesamtprojekt zu gefährden
Der Kunde nahm in einem ersten Schritt die Aufteilung der Wellenplanung auf Ebene von BW InfoAreas vor. Basierend auf diesen Vorgaben identifizierten wir die betroffenen CompositeProvider mithilfe der Entity-Listen in der Performer Suite. Wir erstellten Listen dieser Provider, angereichert mit zusätzlichen Attributen, und stellten sie dem Kunden zur Verfügung. Dies ermöglichte eine präzise Nachjustierung der Planung, da nicht alle CompositeProvider aus einer InfoArea aufgrund von Abhängigkeiten zwangsläufig in der gleichen Welle migriert werden konnten.
Unsere Aufgabe war es, die Datenflüsse je Composite Provider vollständig und reibungslos mit dem BW Conversion-Tool als Shell-Conversion zu migrieren. Obwohl das Conversion Tool Abhängigkeiten durch eine Scope-Analyse selbst ermitteln kann, erwies es sich als sinnvoll, die Objekte manuell auf mehrere Conversion Tasks zu verteilen. Die automatische Scope-Analyse liefert oft sehr umfangreiche Objektlisten, was das Risiko von Abbrüchen bei komplexen Abhängigkeiten erhöht. Zudem werden bestimmte Abhängigkeiten, wie Lookups in ABAP-Transformationen, nicht automatisch erkannt.
Unsere Lösung bestand darin, den Scope pro Conversion-Schritt manuell zu definieren, um damit eine bessere Handhabbarkeit zu erreichen und die Migrationskomplexität zu reduzieren. Basierend auf dieser Vorgehensweise entwickelten wir folgende Priorisierung für die Migration:
- InfoProvider (InfoObjekte, aDSOs, Composite Provider)
- Übertragung nativer DDIC-Objekte via ABAPGit in den ABAP Stack der BW Bridge (z.B. Lookups auf Z-Tabellen in Transformationen, Auslagerung von Routinen-Coding in ABAP-Klassen)
- Transformationen
- DTPs und Prozessketten
Die DDIC-Objekte mussten manuell auf der BTP ABAP Cloud Umgebung der BW Bridge angepasst und aktiviert werden. Diese Umgebung ist restriktiver als ABAP Classic und erlaubt nur von SAP freigegebene APIs. Die meisten bestehenden ABAP-Entwicklungen erforderten daher ein erhebliches Refactoring.
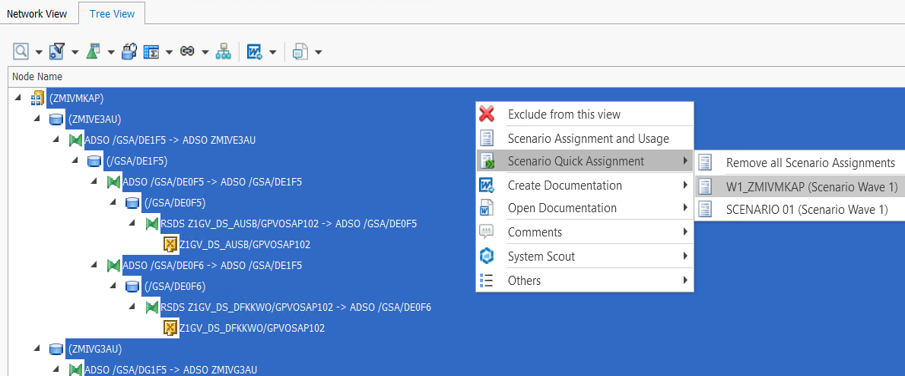
Für die Erstellung der Scope-Listen benötigten wir pro Composite-Provider eine vollständige Auflistung aller Objekte des Datenflusses, einschließlich Transformationen und DTPs. Hierfür nutzten wir die Datenfluss-Analyse in der Performer Suite. Diese ermöglichte es uns, alle Objekte des Datenflusses einem Szenario (in unserem Fall einer Migrationswelle) zuzuordnen:
Anschließend konnten wir in der Entity-Liste der Performer Suite alle Objekte durch Selektion auf das entsprechende Szenario auswählen und als Liste ausgeben.
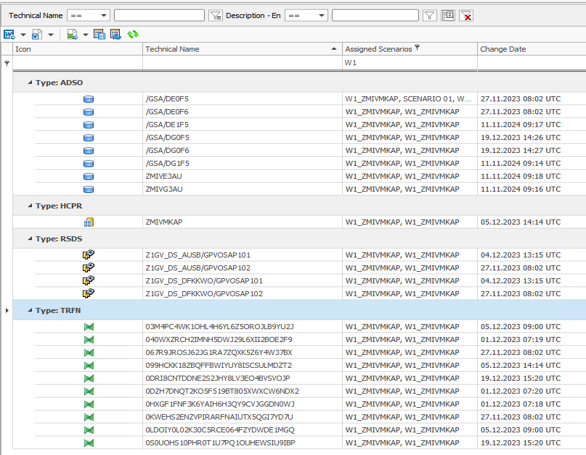
Diese Listen dienten als Arbeitslisten für die Migration und wurden mit zusätzlichen Informationen (z.B. Transformation verwendet ABAP-Coding) und dem Migrationsstatus angereichert. Dieser Ansatz erlaubte uns eine transparente und strukturierte Verwaltung der zu migrierenden Objekte für jede Welle.
Weitere Anwendungsbereiche im Projektverlauf
Die Performer Suite erwies sich als vielseitiges Werkzeug in unserem Migrationsprojekt. Besonders wertvoll waren die einfachen Möglichkeiten, schnell Listen von BW-Objekten für verschiedene Zwecke zu erstellen.
- Für Ad-hoc Analysen bot die Suite (speziell der System Scout) schnelle Einblicke in Datenflüsse, die sich als detaillierter und benutzerfreundlicher erwiesen als die Datenfluss-Ansicht in den BW-Modelling-Tools.
- In Fällen, in denen Modelle nicht migriert, sondern archiviert wurden, nutzten wir die Suite zur schnellen Erstellung von kompletten Modell-Dokumentationen
- Für die Entwicklungstests war die Suite besonders nützlich, um schnell zu ermitteln, welche InfoProvider über welche Prozessketten geladen werden. Diese schnelle Übersicht hat uns dabei geholfen, den Testprozess für die Entwicklungstests effizienter zu managen.
Herausforderungen und Erkenntnisse im Projektverlauf
Im Laufe des Projekts stießen wir als Berater trotz Tool-Support natürlich auch auf Herausforderungen und Limitationen. Dies betraf vor allem Einschränkungen seitens SAP, aber auch Möglichkeiten, die die Performer Suite (noch) nicht bietet.
Der Export der Query Set Cards erwies sich für 3.x Query-Versionen als problematisch, was manuelle Überprüfungen erforderlich machte. Bei größeren Query-Selektionen traten gelegentlich Abbrüche auf, sodass wir die zu einem Composite Provider gehörenden Queries auf mehrere Export-Jobs aufteilen mussten. Die Konsolidierung der einzeln dokumentierten Queries auf einem Sheet erforderte zusätzlichen Aufwand, den wir durch ein selbst entwickeltes Makro bewältigten. Eine zielgerichtetere Analyse aller globalen und lokalen Kennzahlen eines Composite Providers, beispielsweise als System Scout Analyse, wäre hier zukünftig wünschenswert.
Das größere Hindernis für unseren Ansatz der Master-Queries waren die umfangreichen Restriktionen beim Entity-Import in Datasphere, die in einer SAP Note detailliert aufgeführt sind (https://me.sap.com/notes/2932647). Der Importprozess erwies sich als intransparent, da nicht ersichtlich war, welche Probleme auftraten und manuelle Korrekturen erforderten. Einige Features verhinderten den Import komplett, andere wurden übersprungen, was zu unvollständigen Kennzahldefinitionen führte. Besonders gravierend waren die Einschränkungen bei den unterstützten Formeloperatoren. Die Beschränkung auf lediglich die Grundoperationen (+, -, *, /) macht den Entity-Import für Queries in der Praxis nahezu unbrauchbar. Reale Queries weisen häufig Komplexitäten auf, die weit über diese einfachen Operationen hinausgehen. Angesichts dieser Probleme erwies sich die manuelle Anlage der Kennzahlen in Datasphere letztendlich als effizienter. Wir beschränkten den Entity-Import auf die Composite Provider, aus denen wir dann die Analytic Models erstellten, und legten die Kennzahlen manuell in den Analytics Models an. Dabei nutzten wir die Listen der Query Set Cards als Grundlage, die wir für die Master Queries erstellt hatten.
Bei der Erstellung der Objektlisten für die Migrationswellen stießen wir in der Performer Suite auf eine weitere Herausforderung: Die Datenfluss-Analyse ermöglichte keine direkte Zuordnung der DTPs zu den Szenarien. Wir mussten in der Entity-Ansicht über die Parent-Spalte iterativ die InfoProvider aus dem Szenario abprüfen, um festzustellen, welche DTPs zu welchen InfoProvider gehören, und diese dann nachträglich dem Szenario zuordnen. Eine einfachere Funktionalität zur ganzheitlichen Erfassung aller Komponenten eines Datenflusses, einschließlich DTPs, ohne die Notwendigkeit von Workarounds, hätte den Prozess erheblich vereinfacht und beschleunigt.
Fazit und Ausblick
Abschließend lässt sich sagen, dass der Einsatz der Performer Suite sich in unserem Projekt als äußerst wertvoll erwiesen hat, um den manuellen Aufwand und potenzielle Fehlerquellen zu reduzieren und den gesamten Migrationsprozess zu beschleunigen. Die Projektlizenz bot den Vorteil, dass wir (NextLytics) nur eine temporäre Lizenz für den spezifischen Anwendungsfall erwerben mussten. Unser Anspruch war es nicht, die Performer Suite in den Alltag der IT zu integrieren, sondern sie gezielt für unseren Zweck zu nutzen. Daher war auch kein Expertenwissen in allen Facetten des Tools erforderlich.
Wir sind uns bewusst, dass wir möglicherweise noch mehr hilfreiche Informationen aus dem Tool hätten herausholen oder direkt mit den Listen im Tool hätten weiterarbeiten können. Oft griffen wir auf die altbewährte Methode zurück, die wir bei Kunden häufig sehen und vor der wir normalerweise warnen: Den Export nach Excel, gefolgt von einer kreativen Weiterbearbeitung der Daten. Aber manchmal muss man eben pragmatisch sein! Wenn es für die Projektbeteiligten, die nicht alle Zugang zum Tool hatten, einfacher war, mit Objektlisten in der vertrauten Umgebung von Excel zu arbeiten, dann war das von unserer Seite völlig in Ordnung.
Neben den bereits genannten Features im Hinblick auf Kennzahlen- und Datenfluss-Analyse sehen wir noch spannendes Potenzial für zukünftige Erweiterungen, die den Nutzen der Performer Suite in solchen Projekten weiter steigern könnten:
- Mehr ABAP-basierte Informationen in der Datenfluss-Analyse, insbesondere im Hinblick auf die ABAP Cloud Sprachsyntax. Es wäre beispielsweise sehr hilfreich, wenn man in der Datenfluss-Analyse sehen könnte, welche Transformationen ABAP-Coding verwenden, das nicht ABAP Cloud-kompatibel ist.
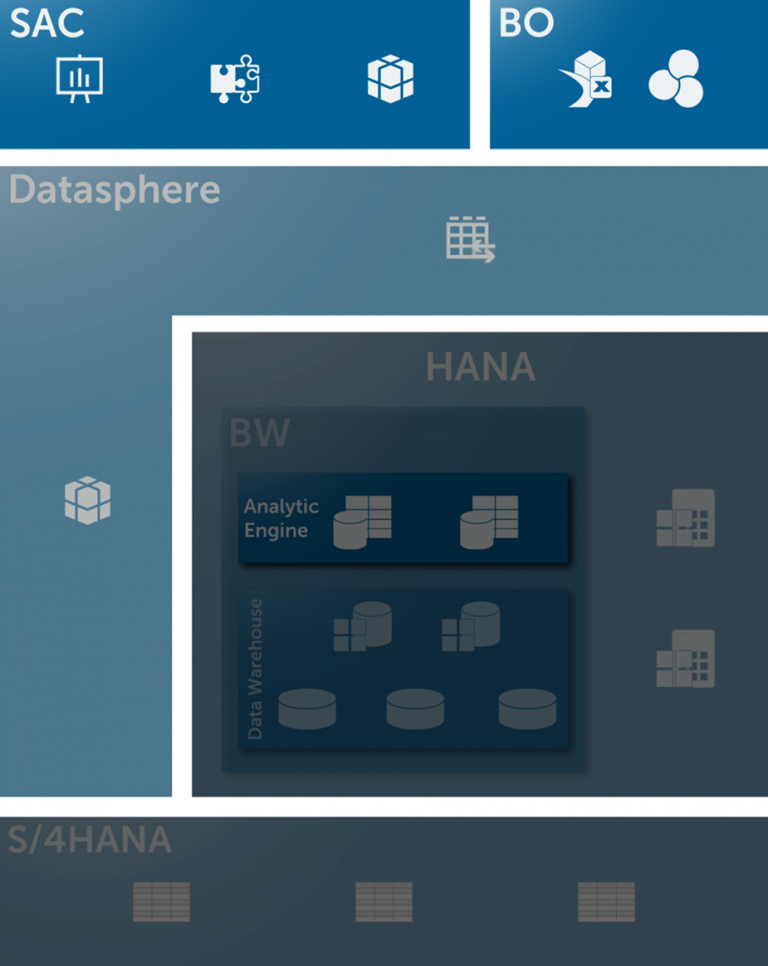
- Es ist erfreulich zu sehen, dass bluetelligence massiv in den Ausbau ihrer Analysen Richtung SAP Datasphere und SAP Analytics Cloud investiert. Neben Views werden künftig auch Analytics Models und Task Chains über die Performer Suite analysierbar sein, was in Migrationsprojekten beim Abgleich der alten BW-Welt mit der neuen Datasphere-Welt helfen wird. Mit unserer aktuellen Version des Tools konnten wir uns leider nur gegen das alte BW-System verbinden, nicht jedoch gegen Datasphere bzw. BW Bridge.
- Ideal wäre es natürlich, wenn der Migration Booster, der als Migrationssupport für BW zu BW/4HANA dient, künftig auch für BW Bridge-Projekte genutzt werden könnte. Dieser ermöglicht im Vergleich zum SAP Conversion Tool eine deutlich komfortablere und gezieltere Migration und erlaubt auch die Vergabe neuer Namenskonventionen. Ob SAP hierfür die APIs auf der BTP bereitstellt bzw. ob der Markt für BW Bridge-Migrationen groß genug ist, um eine solche Investition zu rechtfertigen, ist fraglich. Aber man darf sich ja noch was wünschen, ist ja bald Weihnachten 🙂
Zum Schluss an dieser Stelle noch der Hinweis seitens bluetelligence, dass Sie über das bei der Migration eingesetzte Tool, den System Scout, hier mehr erfahren:
Dieser Artikel beleuchtet die Herausforderungen und Lösungsansätze im Bereich ABAP-Programmierung, die als zentrale Programmiersprache im SAP-Umfeld dient. Im ersten Teil wird ABAP vorgestellt, einschließlich seiner Rolle bei der Steuerung und Erweiterung von Geschäftsprozessen in Unternehmen und der Vielfalt an ABAP-Objekten. Dann werden typische Herausforderungen im Umgang mit ABAP-Coding in großen Unternehmen beschrieben. Zum Schluss wird der Einsatz automatisierter AddOn-Tools beleuchtet, die Transparenz und Effizienz in der ABAP-Entwicklung steigern. Anhand eines Use Cases wird gezeigt, wie diese helfen, Code-Strukturen und Abhängigkeiten schneller und präziser zu analysieren sowie zu dokumentieren.
1. ABAP-Code verstehen: Definition, Einordnung und zugehörige Objekte
ABAP (Advanced Business Application Programming) ist eine von SAP entwickelte Programmiersprache, die hauptsächlich für die Entwicklung von Anwendungen im SAP-Umfeld verwendet wird. Mit der SAP als weltweit führendes Unternehmen für Unternehmenssoftware ist ABAP damit eine der Hauptsprachen, wenn es darum geht, Geschäftsprozesse innerhalb von Anwendungen zu steuern und zu erweitern.
Obwohl ABAP ursprünglich prozedural war, unterstützt es heute auch objektorientierte Programmierung, ähnlich wie Java oder C++. Dies erleichtert es, moderne Softwareentwicklungsprinzipien zu implementieren.
In einem großen Unternehmen kann die Anzahl der ABAP-Objekte (Programme, Klassen, Funktionsbausteine, Reports, Module usw.) in die Zehntausende gehen. Dies umfasst:
- Reports: Programme, die für das Abrufen, Verarbeiten und Darstellen von Daten verwendet werden (mehr Infos dazu gibt es hier)
- Funktionsbausteine: Wiederverwendbare Module in ABAP, die spezifische Aufgaben kapseln und in Programmen aufgerufen werden (mehr Infos dazu gibt es hier)
-
Formulare: Benutzerdefinierte Formulare wie Rechnungen oder Lieferscheine.
-
Erweiterungen: User Exits, BAdIs (Business Add-Ins) und andere Mechanismen zur Anpassung des SAP-Standards.
2. Herausforderungen im ABAP-Coding meistern
Gewachsene Entwickler-Teams in großen Unternehmen haben angesichts der Fülle an ABAP-Coding häufig mit intransparenten Abhängigkeiten zu kämpfen. Die Folge sind Fehler, eine erhöhte Datenmodell-Komplexität, schwere Wartbarkeit und Risiken bei Systemupdates. Wie diese Anhängigkeiten überhaupt zustande kommen, erläutern wir im Folgenden:

a) Fehlende oder unzureichende Dokumentation vermeiden
Eine der häufigsten Ursachen für intransparente Abhängigkeiten ist eine unzureichende oder nicht vorhandene Dokumentation. In vielen Projekten wird der Fokus auf die Entwicklung von Funktionalität gelegt, während der Dokumentationsaspekt vernachlässigt wird. Es ist jedoch essentiell, für die “Nachwelt” festzuhalten, wie verschiedene Programme, Module und Datenstrukturen miteinander verknüpft sind. Ohne klar definierte Anforderungen, zugewiesene Verantwortliche und die kontinuierliche Aktualisierung der Dokumentation wird es schwierig, Abhängigkeiten zu erkennen, denn: Reverse Engineering über mehrere Systemtypen hinweg ist enorm aufwendig.
b) Historisch gewachsenen Code managen
SAP-Systeme und ihre ABAP-Codes bestehen oft über viele Jahre hinweg und werden kontinuierlich angepasst und erweitert. Im Laufe der Zeit entstehen immer mehr benutzerdefinierte Funktionen, schnell implementierte Lösungen, Workarounds und Erweiterungen, die ursprünglich auf kurzfristige Anforderungen reagieren sollten. Selten bis nie wird hier aufgeräumt, alte Module/Programme werden weiterhin verwendet, obwohl neue Lösungen existieren und Änderungen werden zum Teil ohne die Berücksichtigung des Gesamtsystems vorgenommen. So passiert es, dass diese „gewachsenen“ Strukturen nicht mehr klar nachvollziehbar sind, insbesondere wenn verschiedene interne und externe Entwickler oder Teams über die Jahre an denselben Programmen gearbeitet haben.
c) Fehlende Modularität und Wiederverwendung auf dem Schirm haben
In der ABAP-Entwicklung werden häufig globale Daten und Funktionen verwendet, die in vielen verschiedenen Programmen eingebunden sind. Wenn Entwickler globale Klassen, Datenbanktabellen oder Funktionsbausteine nutzen, ohne eine saubere Modularisierung und klare Schnittstellen zu definieren, entstehen enge Abhängigkeiten zwischen verschiedenen Teilen des Systems. Auch das Kopieren von Code anstelle der Nutzung gemeinsamer Bausteine führt dazu. Diese Abhängigkeiten sind oft schwer zu erkennen und nicht immer dokumentiert.
d) Ungeplante und unkoordinierte Anpassungen vermeiden
In größeren SAP-Installationen arbeiten häufig mehrere Entwickler oder Teams gleichzeitig an unterschiedlichen Datenstrukturen und Funktionen. Wenn diese Anpassungen ohne klare Koordination oder Kommunikation erfolgen, keine Versionierung abrufbar ist oder Code-Review-Prozesse fehlen, können Abhängigkeiten entstehen, die den Beteiligten nicht bewusst sind. Diese Abhängigkeiten bleiben dann intransparent, bis sie durch einen Fehler oder ein Problem offensichtlich werden.
e) Verwendung von dynamischen und indirekten Aufrufen richtig regeln
In ABAP besteht die Möglichkeit, dynamische Programmaufrufe und indirekte Zugriffe zu verwenden, um generische Lösungen zu implementieren (z. B. dynamische Funktionsaufrufe oder SELECTs auf Tabellen, deren Namen erst zur Laufzeit bestimmt werden). Auch werden zum Teil Metadaten oder Tabellen zur Laufzeit genutzt, um Programmabläufe zu steuern. Solche Techniken können nützlich sein, um flexible Lösungen zu entwickeln, aber sie machen den Code weniger nachvollziehbar. Ohne klare Referenzen zu den abhängigen Modulen wird es schwieriger, nachzuvollziehen, welche Programme oder Datenstrukturen tatsächlich verwendet werden.
f) Enge Kopplung zwischen benutzerdefinierten und Standard-SAP-Komponenten beachten
„User Exits“, „Enhancements“ oder „Modifikationen“, um den SAP-Standard zu erweitern. sind Gang und Gäbe. Oft werden diese benutzerdefinierte Entwicklungen (Z-Programme, Erweiterungen) stark mit dem SAP-Standard verknüpft. Wenn Änderungen am Standard vorgenommen werden (z. B. durch ein SAP-Upgrade oder ein Support Package), können unvorhergesehene Abhängigkeiten entstehen, da die Programme eng verzahnt wurden, die nicht transparent sind. Die engen Verbindungen zwischen benutzerdefinierten Erweiterungen und dem SAP-Standard können schwer nachvollziehbar sein.
g) Tests und Qualitätskontrollen nicht vernachlässigen
Wenn der Code nicht ausreichend getestet oder überprüft wird, können Abhängigkeiten übersehen werden. Tests, insbesondere Unit- und Integrationstests, decken oft versteckte Abhängigkeiten auf, die durch Änderungen in einem Modul oder Programm verursacht werden. Wenn solche Tests nicht stattfinden oder unzureichend sind, bleiben diese Abhängigkeiten lange unerkannt und Änderungen mit Fehlern in die Produktion gebracht. Dieser Aspekt ist also einem Mangel an Qualitätssicherungsprozessen geschuldet.
3. Tool-Unterstützung: Automatisierte Transparenz im ABAP-Coding
Die Herausforderungen mit ABAP-Coding sind, wie oben beschrieben, vielseitig und bedeuten eine Menge Aufwand in Bezug auf Dokumentation, Abstimmung und Qualitätssicherung. SAP AddOn-Tools können diese Prozesse automatisieren: Sie dokumentieren, können den Code schnell durchsuchen und anpassen, erleichtern Tests und bieten Kollaborationsfunktionen für interne wie externe Beteiligte.
Um sich den Einsatz solcher Tools im Arbeitsalltag nun konkreter vorstellen zu können, hilft ein konkreter Use Case:
Sie sind ABAP-Entwickler. Seit einiger Zeit wundern Sie sich, warum für den Buchungskreis 2000 in der Tabelle ACDOCA der Record Type immer auf Plan steht. Leider haben Sie keinen Zugriff mehr auf die ursprünglichen Entwickler, die diese Prozesse implementiert haben, weil diese das Unternehmen längst verlassen haben. Sie stehen also vor der Herausforderung, die Herkunft der Daten in dieser Tabelle ohne Tipps oder Dokumentationen zu ermitteln.
Statt sich mühsam durch das SAP BW-Backend zu kämpfen und manuell nach den relevanten ABAP-Objekten zu suchen, nutzen Sie ein SAP AddOn-Tool, das Metadaten automatisch durchsuchen und in Zusammenhang stellen kann. Ein solches Tool ist zum Beispiel unsere Software “System Scout”. Über seine Funktion „ABAP Relations“ können Sie Beziehungen zwischen verschiedenen ABAP-Objekten und der Tabelle ACDOCA auf Knopfdruck analysieren. So entdecken Sie, dass das Programm Z_UPDATE_ACDOCA die Tabelle ACDOCA manipuliert.
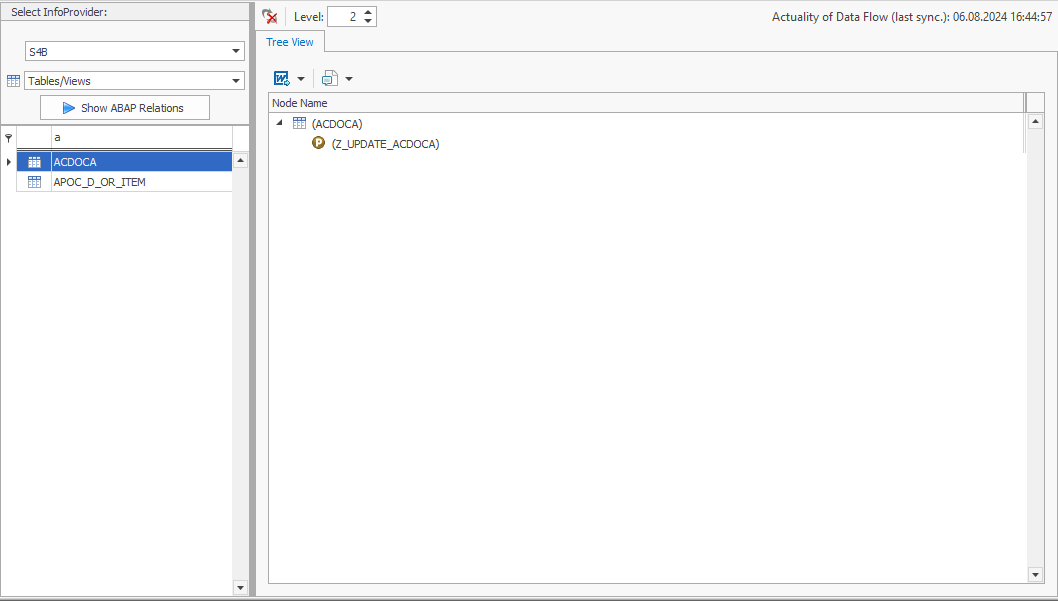
INSERT, MODIFY, UPDATEund DELETE Sie brauchen aber noch mehr Informationen: Ihnen ist es wichtig, zu wissen, welche ABAP-Objekte die Datenmanipulation auslösen. Auch hier bietet das Tool eine hilfreiche Funktion: Den Verwendungsnachweis. Er führt diese Analyse für das Programm Z_UPDATE_ACDOCA durch und findet heraus, dass dieses Programm im Funktionsbaustein Z_FM_ACC referenziert wird:
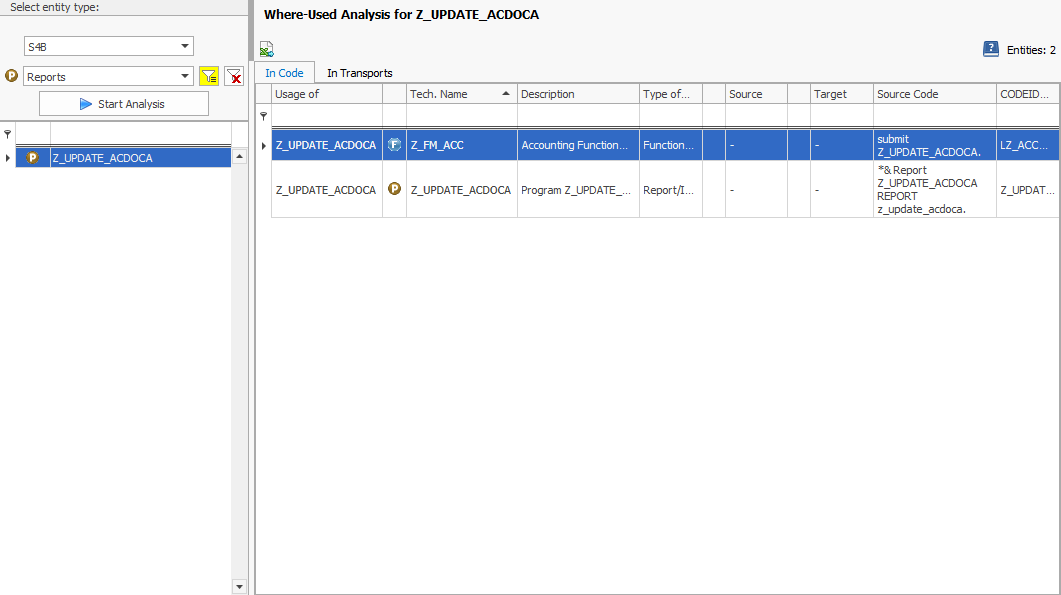
Der Hinweis darüber, wo Sie nach der Logik suchen sollen, die für den Record Type Plan verantwortlich ist, spart Ihnen bei fehlender Dokumentation und einer vollen To Do-Liste wertvolle Zeit.
Nach der automatisierten Analyse des Quellcodes finden Sie außerdem heraus, dass eine sehr alte Logik aus 2012 den Record Type für den Buchungskreis 2000 immer auf Plan setzt.
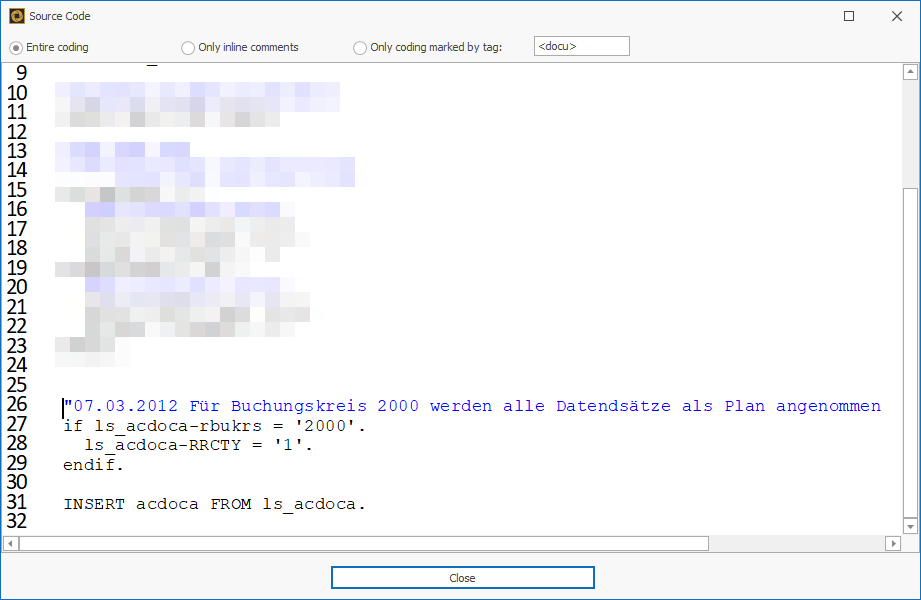
Übrigens: Abgesehen vom aufgeführten Use Case im klassischen ABAP-Umfeld unterstützt Sie die Funktion „ABAP Relations“ auch im BW-Umfeld. Wird in einem BW-Datenfluss ein Lookup-Scan durchgeführt, können die identifizierten Objekte anschließend nämlich ebenfalls mit „ABAP Relations“ analysiert werden:
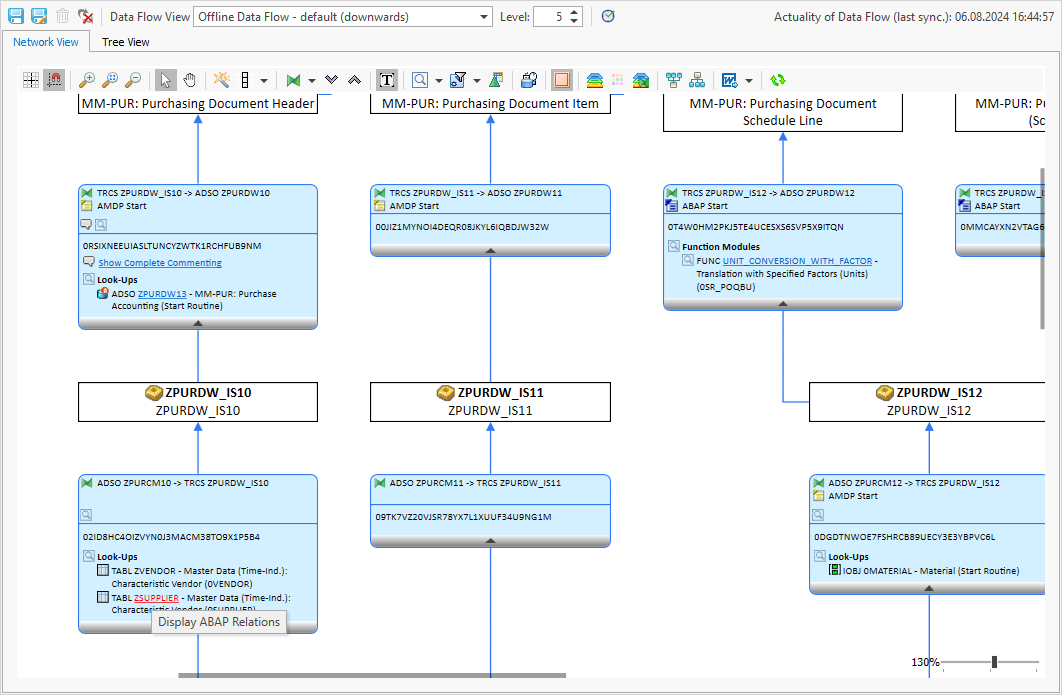
So erkennt man beispielsweise, dass die Tabelle ZSUPPLIER von einem Programm – nämlich Z_UPDATE_SUPPLIER – manipuliert wird:
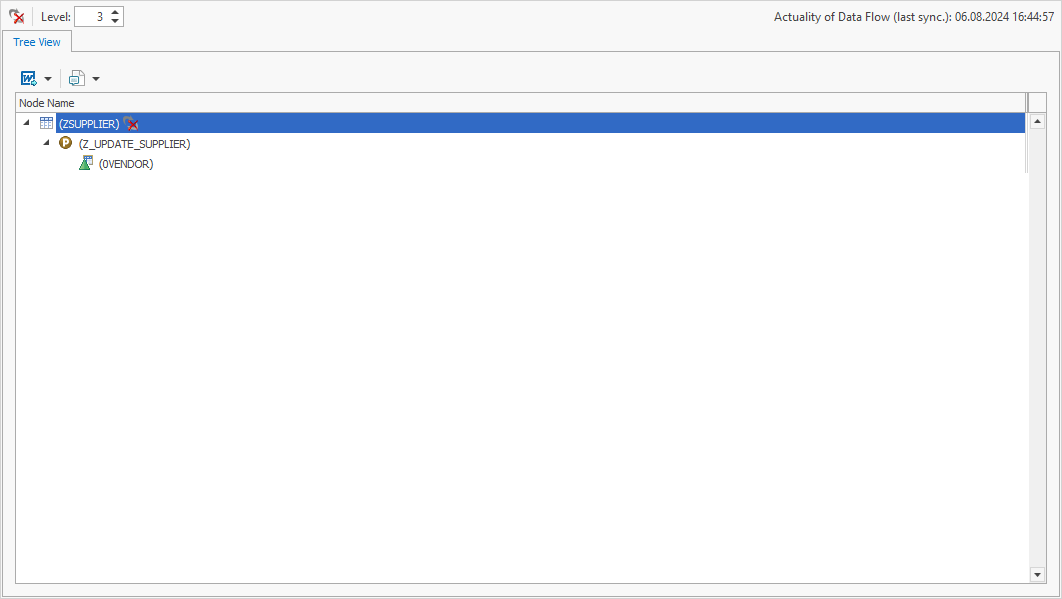
Zusätzlich werden identifizierte Tabellen von BW-Objekten direkt als BW-Objekte angezeigt. Das sorgt für ein besseres Verständnis und ermöglicht weitere Interaktionen und Analysen.
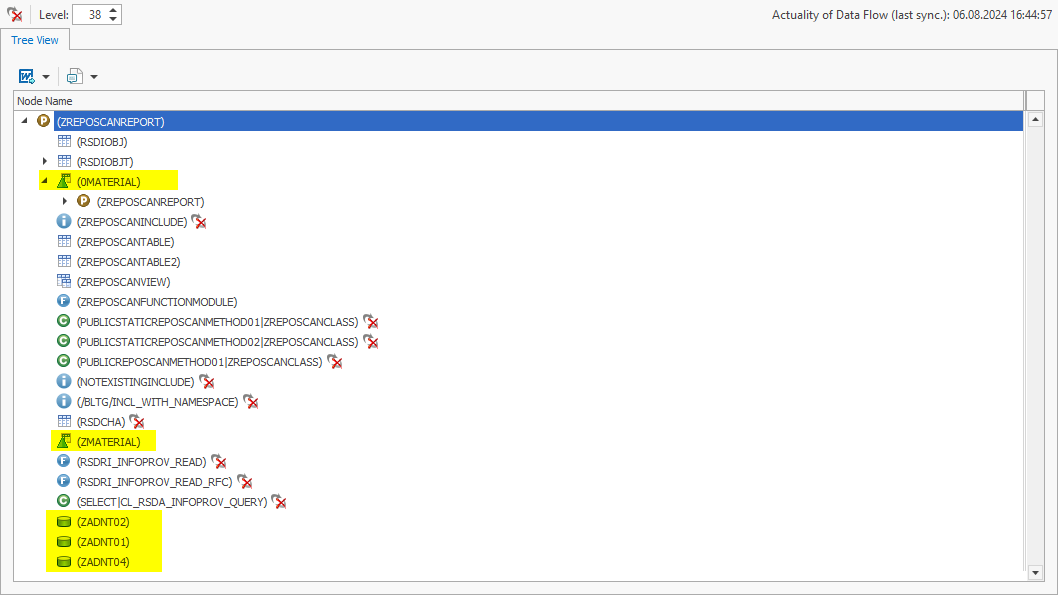
Die Funktionen des Tools System Scouts, hier insbesondere „ABAP Relations“ und der Verwendungsnachweis, bieten ABAP-Entwicklern, die komplexe Datenflüsse schnell nachvollziehen müssen, erhebliche Vorteile:
-
Sie ermöglichen einen schnellen Überblick über Datenmanipulationen und deren Herkunft, sparen Zeit und erhöhen die Genauigkeit der Analysen.
-
Durch die klare Darstellung der Beziehungen zwischen verschiedenen ABAP-Objekten und Tabellen schaffen diese Funktionen Transparenz und erleichtern die Arbeit erheblich.
-
Zudem wird durch die Unterstützung im BW-Umfeld die gesamte Datenflussanalyse in SAP-Systemen noch effizienter und verständlicher.
P.S.: Niemand bleibt ewig auf seinem Posten – vergessen Sie für Ihre Nachwelt also nicht, ABAP-Objekte und deren Beziehungen zu dokumentieren. Auch dafür gibt es ein SAP AddOn-Tool, das automtisiert handelt – den Docu Performer. Er stellt sicher, dass zukünftige ABAP-Entwickler nicht mehr recherchieren müssen, sondern direkt auf detaillierte und tagesaktuelle Dokumentationen zugreifen können.
Kollaboration ist ein entscheidender Erfolgsfaktor, insbesondere in komplexen Bereichen wie der Business Intelligence (BI) eines Unternehmens. Wo Wissen und Skills von Mitarbeitenden vereint werden, kann Großes entstehen – und vieles geht effizienter von statten. Durch Kollaboration kann das BI-Team schneller auf Veränderungen reagieren, flexibler handeln und letztlich das Ergebnis und die Wettbewerbsfähigkeit des Unternehmens positiv beeinflussen.
Da Verantwortlichkeiten und Entscheidungen im BI-Bereich fast ausschließlich Diagramme und Berichte betreffen, setzt Collaborative BI vor allem dort an. Die Ausgangslage: Die meisten Unternehmen setzen High-End-Softwarelösungen für Reports ein, haben jedoch mit einer geringen Nutzung und Akzeptanz in ihren Teams zu kämpfen. Der Collaborative BI-Ansatz steigert die Akzeptanz von BI-Software und verändert gleichzeitig die Art und Weise, wie wir mit Datenanalysen und Entscheidungsfindung umgehen – indem wir die Teamarbeit fördern und das Wissen aller Beteiligten zusammenführen. Im Folgenden wird beleuchtet, wie das aussehen kann.
1. Collaborative BI verstehen
Um ein tieferes Verständnis von Collaborative BI zu bekommen, werfen wir zunächst einen Blick auf die „traditionelle“ Business Intelligence, also vor Einsetzen dieses Trends. Traditionelle Business Intelligence folgt einem zentralisierten, IT-gesteuerten Modell, bei dem ein spezialisiertes Team von Analyst:innen statische, historische Berichte für Entscheidungsträger erstellt. Die Fertigstellung der Berichte kann sich gut und gerne mal etwas verzögern, denn Informationen müssen zusammengesucht und Abhängigkeiten berücksichtigt werden.
Collaborative BI hingegen ermöglicht einer größeren Anzahl von Benutzern im gesamten Unternehmen die Interaktion mit dynamischen Echtzeitdaten mit Hilfe von Self Service-Tools, die die Abhängigkeit von der IT verringern. Diese Methode und die dazugehörigen Tools fördern eine bessere Zusammenarbeit durch Funktionen wie die gemeinsame Nutzung von Berichten, Kommentaren und Anmerkungen und legen gleichzeitig den Schwerpunkt auf Echtzeit- und prädiktive Analysen, um eine proaktive Entscheidungsfindung zu erleichtern.

Traditionelle BI versus Collaborative BI
Ziele bei der Implementierung von Collaborative BI
Die Hauptintention von Collaborative BI ist die Verbesserung von Problemlösungs- und Entscheidungsprozessen: Man will handlungsfähiger werden. Die folgenden Aspekte sind für das Erreichen dieses übergeordneten Ziels von grundlegender Bedeutung:
Dezentralisierte Analysen
Der Punkt mag nach dem, was wir bisher über Collaborative BI gehört haben, paradox klingen, bezieht sich jedoch eher auf den Aspekt des Schwarmwissens: Durch die Einbindung und Befähigung einer Vielzahl von Benutzern mit unterschiedlichen Rollen, Hintergründen und Fähigkeiten können Unternehmen auch reichere Perspektiven einnehmen. Dieser Ansatz trägt dazu bei, Bottle Necks zu vermeiden, die traditionell mit zentralisierten BI-Teams verbunden sind, und beschleunigt so den Problemlösungsprozess.
Optimiertes Dashboard- & Berichtsdesign
Benutzer mit unterschiedlichen Rollen, Hintergründen und Qualifikationsniveaus benötigen indivuelle Dashboards und Berichte, die auf ihre spezifischen Bedürfnisse abgestimmt sind. Durch die Förderung des Ideen- und Wissensaustauschs zwischen diesen Nutzern, beispielsweise über Kommentarfunktionen, können Unternehmen maßgeschneiderte Dashboards und Berichte erstellen, die den unterschiedlichen Anforderungen ihrer Zielgruppe gerecht werden. Darüber hinaus ermöglicht der Aspekt des Echtzeitzugriffs auf Daten den Usern, Probleme schneller zu erkennen und zu lösen. Interaktive Dashboards und Berichte, die beispielsweise Absprünge erlauben, ermöglichen es Usern darüber hinaus, die Daten tiefer zu durchdringen und Ursachen und Muster schneller aufzudecken als bei statischen Berichten.
Kollaborative Tools
Kollaborative BI-Tools bieten die genannten Funktionen wie Kommentare, Freigaben und Diskussionsstränge, die die unmittelbare Kommunikation und Zusammenarbeit zwischen den Teammitgliedern erleichtern und einen schnelleren Konsens und schnelleres Handeln ermöglichen. Der nahtlose Datenaustausch in Echtzeit im gesamten Unternehmen stellt sicher, dass alle relevanten Interessengruppen auf dieselben Informationen zugreifen können, und fördert so einen einheitlichen Ansatz für die Entscheidungsfindung. Mit Self-Service-BI-Tools können Benutzer ihre eigenen Berichte und Abfragen erstellen, ohne auf die Unterstützung der IT-Abteilung warten zu müssen, was den Entscheidungsprozess beschleunigt.
2. Herausforderungen bei der Implementierung von Collaborative BI
Wie jede neue Implementierung bringt natürlich auch Collaborative BI eine Reihe von Herausforderungen mit sich, die je nach Ausgangsposition des Unternehmens und den aktuellen Umständen unterschiedlich sein können. Die Bewältigung dieser Herausforderungen wird den Erfolg Ihrer Collaborative BI-Implementierung sicherstellen.
- Tool-Elastiziät
- Datenschutz, Sicherheit und Data Ownership
- Metadaten
- Daten-Integration
- Kommunikation zwischen Mitarbeitern

Tool-Elastizität
Die Elastizität von BI-Tools, d.h. die Fähigkeit zur Skalierung und Anpassung an wechselnde Benutzerbedürfnisse, stellt auch bei der Implementierung von Collaborative BI eine Herausforderung dar: Die Gewährleistung der Skalierbarkeit ohne Performance-Einbußen, die Integration in bestehende Systeme, die Verwaltung variabler Kosten und die Erleichterung der Benutzerakzeptanz auf allen Qualifikationsniveaus erfordern einige Anstrengungen. Darüber hinaus erschweren mitunter Bedenken zur Datensicherheit, insbesondere bei Cloud-basierten Lösungen, die Performance-Optimierung, die Aufrechterhaltung eines konsistenten und zuverlässigen Zugriffs und der Ausgleich zwischen Anpassung und Stabilität den Prozess. Diese Faktoren machen es für Unternehmen schwierig, elastische BI-Tools für die Zusammenarbeit effektiv zu implementieren und zu pflegen.
Datenschutz, Sicherheit & Data Ownership
Datenschutz, Sicherheit und Data Ownership stellen bei der Implementierung von Collaborative BI natürlich eine Herausforderung dar: Der Umgang mit sensiblen Informationen, die Verwaltung der authorisierten Nutzerzugriffe, die Einhaltung von Vorschriften und die Bewältigung des erhöhten Risikos von Datenschutzverletzungen sind komplex – und entscheidend für das Bestehen eines Tools. Darüber hinaus erfordert die Implementierung dieser robusten Sicherheitsmaßnahmen nicht gerade wenig Budget und Know-How. Kontinuierliche User-Schulungen sind unerlässlich, um menschliche Fehler zu minimieren, die die Datensicherheit gefährden könnten.
Metadaten
Metadaten sind im Zusammenhang mit Collaborative BI sehr wichtig, da sie die Fragen nach der Herkunft und Verwendung der Daten beantworten. In der traditionellen BI werden diese Fragen von den Fachabteilungen gestellt und von der IT beantwortet. In der Collaborative BI finden die Business User diese Antworten selbstständig. Dies stellt jedoch die Herausforderung dar, sicherzustellen, dass die Daten auch von weniger technisch-versierten Usern richtig verstanden und im gesamten Unternehmen genutzt werden können – z.B. durch eine unkomplizierte Darstellung und über Schulungen. Darüber hinaus sind Metadaten nur dann für korrekte Analysen von Nutzen, wenn sie aktuell gehalten werden – dies erfordert einen erheblichen Aufwand und eine ständige Dokumentation von beispielsweise Data Sources, Definitionen, Data Lineage und Verwendung. Fehler in den Metadaten können zu Fehlinterpretationen führen, was die gemeinsame Nutzung von Daten und die Zusammenarbeit erschwert.
Datenintegration
Die Datenintegration ist eine besondere Herausforderung und entscheidend für Collaborative BI: Es geht darum, verschiedene Datenquellen mit unterschiedlichen Formaten, Strukturen und Qualitätsstufen in ein einheitliches System zu konsolidieren, auf das alle Benutzer zugreifen und es analysieren können. Sie ist unerlässlich, um eine kollaborative Entscheidungsfindung in Echtzeit zu ermöglichen, erfordert jedoch ausgefeilte Tools und Prozesse für die Extraktion, Transformation und das Laden von Daten. Eine effektive Datenintegration erfordert auch die Zusammenarbeit zwischen der IT-Abteilung und den Fachbereichen, um die Datendefinitionen und -standards abzustimmen — eine komplexe, aber wichtige Aufgabe, um sicherzustellen, dass alle Benutzer mit denselben Daten und mit den korrekten Daten arbeiten.
Kommunikation zwischen Mitarbeitenden
Die Kommunikation zwischen Mitarbeitenden ist natürlich der Kern der ganzen Angelegenheit – und stellt auch eine eigene Herausforderung dar: Aufgrund der unterschiedlichen (technischen und geschäftlichen) Fachkenntnisse und des unterschiedlichen Verständnisses von Daten, der unterschiedlichen Sprache, Prioritäten und Perspektiven sind Missverständnisse vorprogrammiert. Sie können zu falschen Dateninterpretationen, fehlerhaften Analysen und schlechten Entscheidungen führen. Es muss fortwährend dafür gesorgt werden, dass alle Beteiligten bei den BI-Zielen, -Prozessen und der -Toolakzeptanz dieselbe Linie fahren. Die Implementierung dieser Kanäle und die Förderung einer Kultur der offenen Kommunikation erfordern ein ständiges Engagement der Führungsebene, um Silos aufzubrechen und die aktive Beteiligung aller Mitarbeiter zu fördern.
3. Empfehlungen zur Integration von Collaborative BI in Ihre bestehende BI-Landschaft
Collaborative BI mag seine Herausforderungen mit sich bringen, aber mit den folgenden Empfehlungen werden Sie diese hoffentlich überwinden – mehr sogar, von den Vorteilen profitieren:
- Self-Service Datenvisualisierung
- Datenqualität Data Governance
- Metadaten-Management Data Cataloging
- Unternehmenskultur Kommunikation

Self-Service & Datenvisualisierung
Self-Service und Datenvisualisierung sind, wie bereits angeführt, Schlüsselfaktoren, wenn es um Collaborative BI geht – beide Aspekte entlasten die IT-Abteilung und machen Daten für alle Abteilungen zugänglich und verständlich. Dazu braucht es:
- intuitive, benutzerfreundliche Tools, die Mitarbeitende aller Kenntnisniveaus befähigen…
- …selbständig auf Daten zuzugreifen, sie zu analysieren und zu visualisieren und so eine datenorientierte Kultur im gesamten Unternehmen zu fördern,
- umfassenden Schulungen, um die Nutzungsrate und Effizienz dieser Tools sicherzustellen
- Customizability – so wird es Usern möglich, Dashboards auf ihre speziellen Bedürfnisse zuzuschneiden und Ergebnisse einfacher mit Kollegen zu teilen,
- starke Data Governance und Echtzeit-Datenzugrif – so wird die Zuverlässigkeit und Relevanz der gewonnenen Erkenntnisse gewährleistet.
Die aktive Ermunterung zu Feedback und die kontinuierliche Verbesserung der Tools auf Basis dieser Benutzererfahrungen – und das kontinuierlich, denn Bedürfnisse entwickeln sich weiter.
Datenqualität & Data Governance
Eine zweite wichtige Voraussetzung für die Einführung von Collaborative BI ist die Verbesserung der Datenqualität. Dies kann durch die Einführung starker Data Governance-Regularien erreicht werden:
Dazu zählen
- standardisierte Dateneingabeprotokolle,
- regelmäßige Datenbereinigung
- Validierungsverfahren
- und klares Data Ownership, um die Verantwortlichkeiten aller Beteiligten zu klären
So kann eine hochwertige Datenqualität gewährleistet werden.
Moderne Datenmanagement-Tools automatisieren sogar die Fehlererkennung und -korrektur und reduzieren Inkonsistenzen damit erheblich. Grundsätzlich fördert auch die Kultur der Transparenz im Kontext von Collaborative BI eine offene Kommunikation über Daten-bezogene Probleme und gemeinsame Lösungsbemühungen, selbst wenn dies manuell geschieht.
Metadaten-Management & Datenkatalogisierung
Schließlich sind die Verwaltung von Metadaten und die Katalogisierung von Daten ein wesentlicher Aspekt, um den Zielzustand von Collaborative BI zu erreichen. Im Idealfall können Sie sogar beides miteinander kombinieren: Über APIs oder spezielle Metadaten-Repositories ist es möglich, SAP- oder Power BI-Metadaten in Ihren Datenkatalog zu integrieren oder daneben aufzubauen.
Wenn Sie einen Datenkatalog in Ihrem Unternehmen implementieren, sollte sichergestellt werden, dass dieser
- jedem Mitarbeitenden zentral zugänglich ist (z.B. als Webapplikation),
- eine intuitive Benutzeroberfläche bietet und (Meta-)Daten einfach verständlich darstellt, so dass Benutzer unterschiedlicher Fachhintergründe in der Lage sind, die Informationen zu verstehen,
- Metadaten wie die Herkunft, die Verwendung und den Aufbau von Daten enthält, um auftretende Reporting-Fragen effizient und an Ort und Stelle beantworten zu können,
- aktuelle (Meta-)daten anzeigt, um dem Titel „Single Point of Truth“ auch gerecht zu werden – denn veraltete Daten sind für die User irrelevant und entziehen dem Katalog seine Relevanz
Kontinuierliche Schulungen und Unterstützung der Mitarbeiter in Bezug auf die Bedeutung und Verwendung von Metadaten tragen dazu bei, dass die Metadaten im Sinne der Collaborative BI dazu beitragen können, effizientere und fundiertere Entscheidungen zu treffen.
Unternehmenskultur & Kommunikation
Nicht zuletzt sind es die Menschen, die ein Unternehmen ausmachen. Um die neue Kultur der Zusammenarbeit zu fördern, sollte das Management:
- auf allen Ebenen des Unternehmens auf Transparenz setzen und aktiv den Austausch von Informationen und Erkenntnissen fördern,
- regelmäßige Schulungen und Workshops durchführen, um die Datenkompetenz zu verbessern und sicherzustellen, dass alle Mitarbeitenden sich in ihrer Fähigkeit, zu BI-Initiativen beizutragen, sicher fühlen,
- Teamarbeit und gemeinsame Problemlösungen anerkennen und belohnen
- darüber hinaus sollt physisch Raum für Kollaboration geschaffen werden – an dezidierten Räumen zum Austausch im BI-Bereich sollte es nicht mangeln
4. Collaborative BI-Tools: Data Catalog trifft Metadaten-Repository
Wie im Artikel beschrieben, sind benutzerfreundliche Datenkataloge und Metadaten-Repositories zwei entscheidende Werkzeuge zur Umsetzung von Collaborative BI in Ihrem Unternehmen. Mit 16 Jahren Erfahrung in der BI Softwareentwicklung hat bluetelligence ein Tool entwickelt, das beides vereint: Unser Datenkatalog „Enterprise Glossary“ enthält sowohl Businessinformationen (Kennzahlen und Berichte) als auch die dazugehörigen Metadaten über angeschlossene SAP- und Power BI-Systeme. Er bietet ideale Voraussetzungen, um Collaborative BI umzusetzen durch:
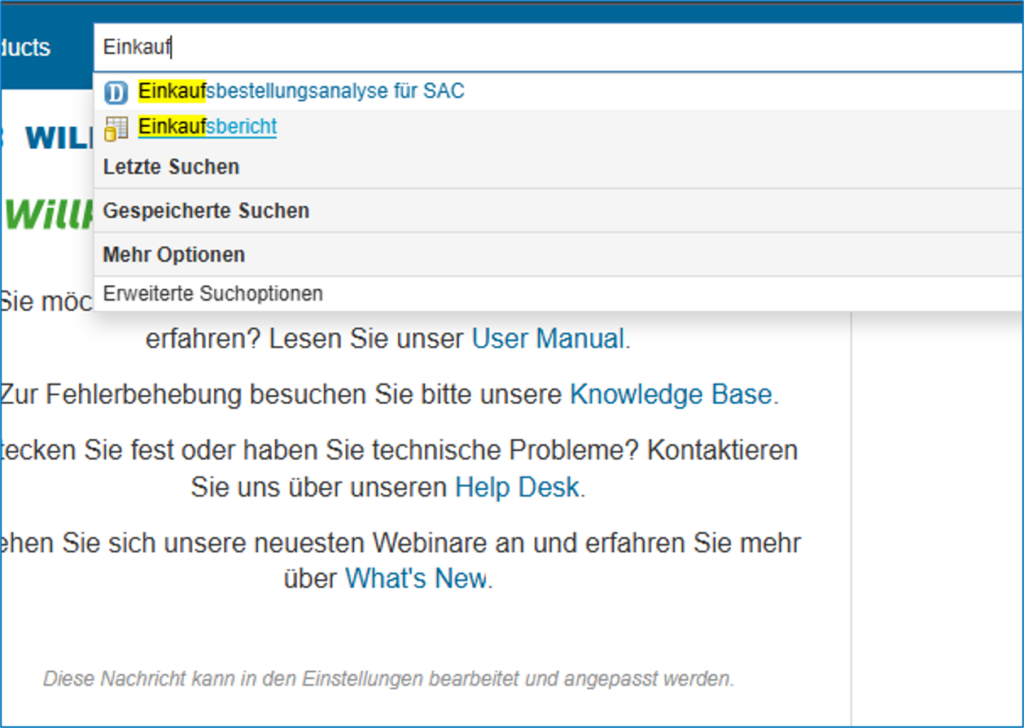
- einen zentralen Zugang zu allen Kennzahlen und Berichten im Unternehmen über den Webbrowser sowie den direkten Absprung dazu
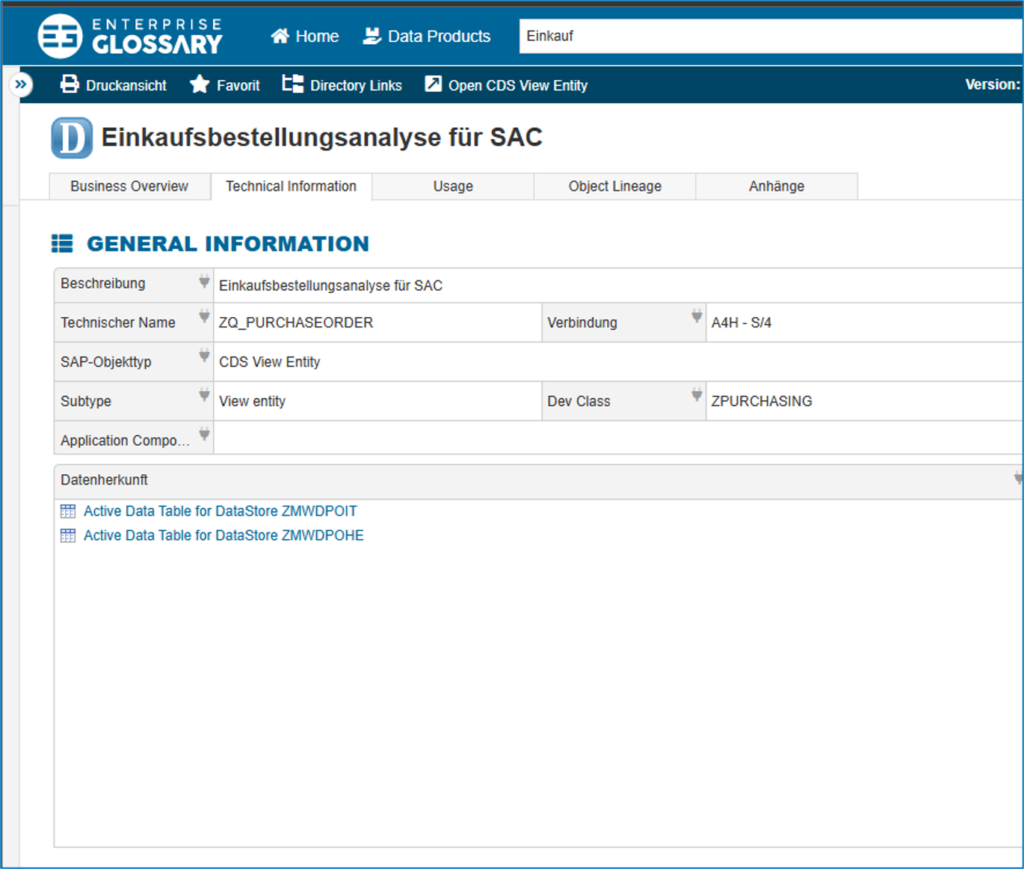
- verständlich aufbereitete Informationen, die technisch- und weniger technich Versierte verstehen können: fachliche Definitionen und Berechnungen sowie dazugehgörige technische Metadaten (Datenquelle, Datenherkunft, abhängige Kennzahlen usw.
- eine benutzerfreundliche Suche und eine intuitiven Oberfläche
- die automatische Synchronisierung aller verbundenen SAP- und Power BI-Systeme für stets aktuelle Informationen
- die Bereitstellung von Kommunikationsfunktionen für Kommentare und Diskussionen
- die Möglichkeit, Standardvorlagen zu verwenden oder die Glossareinträge vollständig an Ihre Bedürfnisse anzupassen
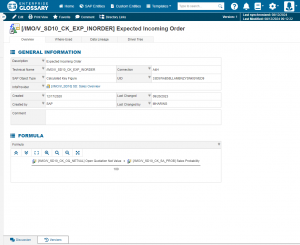
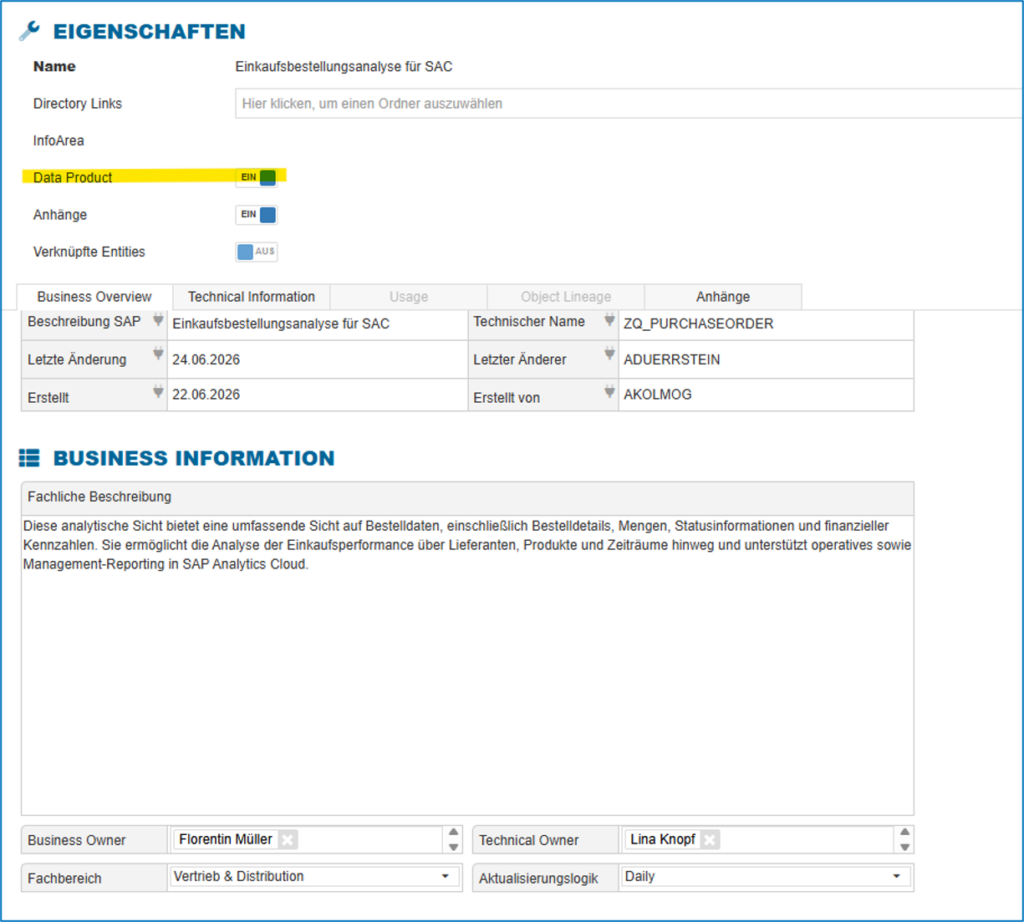
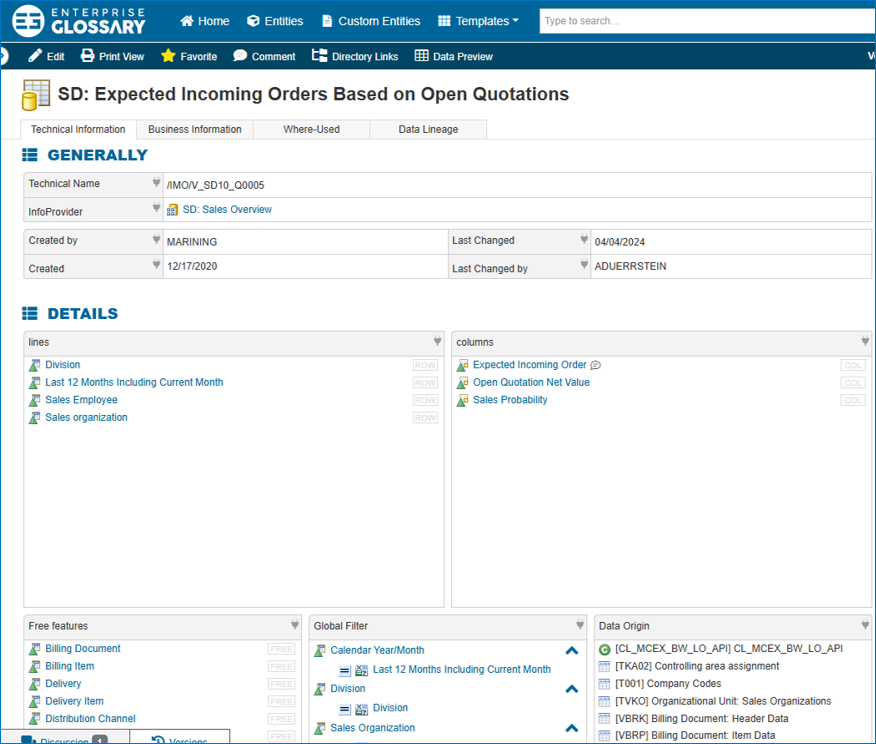
Glossareintrag im Data Catalog „Enterprise Glossary“
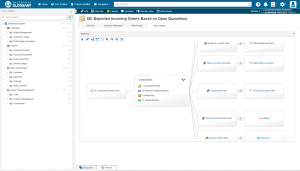
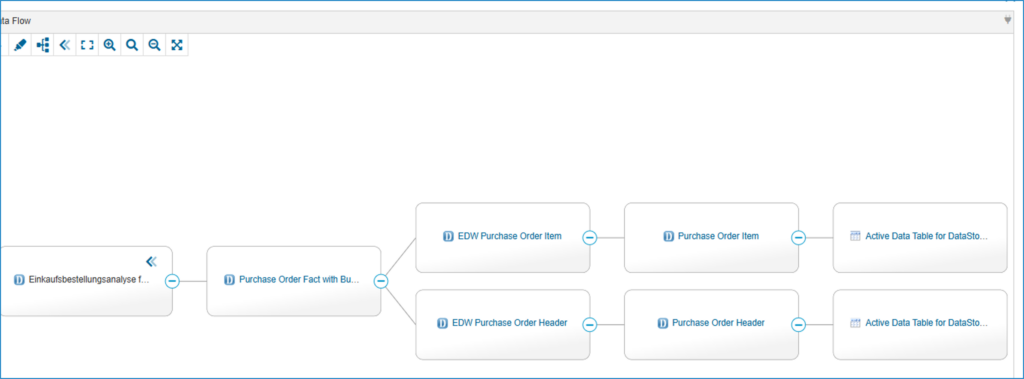
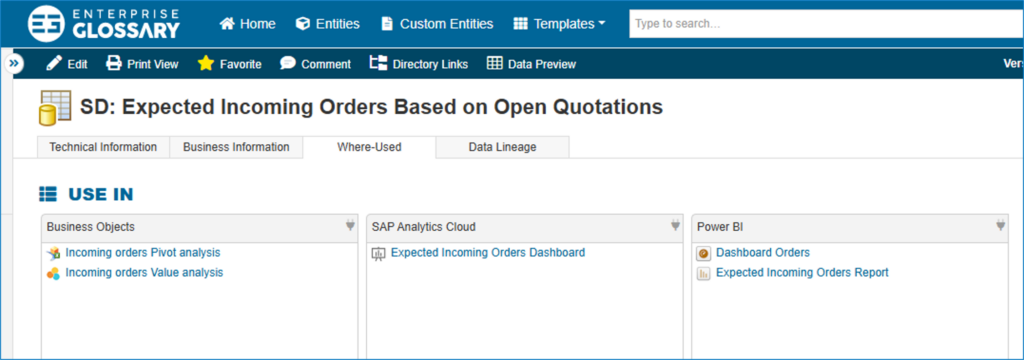
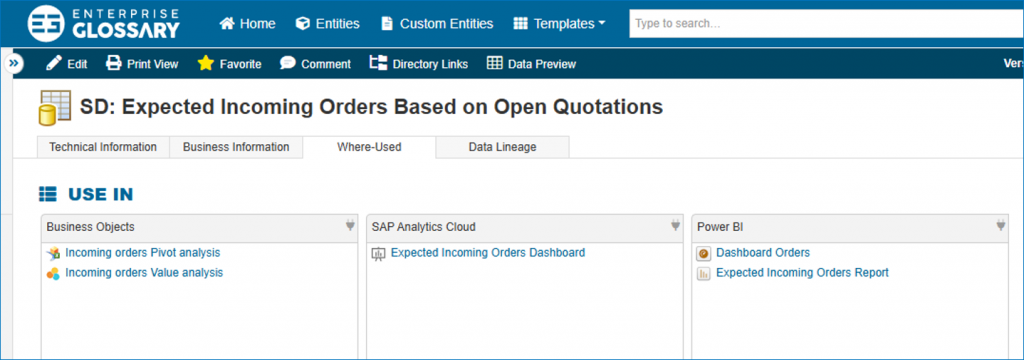
Data Lineage im Data Catalog „Enterprise Glossary“
Unser Data Catalog empowert damit Ihre Fachanwender, entlastet die IT und optimiert Daten-bezogene Prozesse und Kommunikation. Mehr Details zum Enterprise Glossary finden Sie auf www.enterprise-glossary.de.
Wenn Sie bereits einen Datenkatalog verwenden, darüber hinaus aber SAP- oder Power BI-Metadaten einbeziehen möchten, kann unsere API Sie dabei unterstützen. Mehr Infos zur API finden Sie auf www.bluetelligence.de/metadata-api.
